论文: RAFT: Adapting Language Model to Domain Specific RAG, 2024
链接: https://arxiv.org/pdf/2403.10131
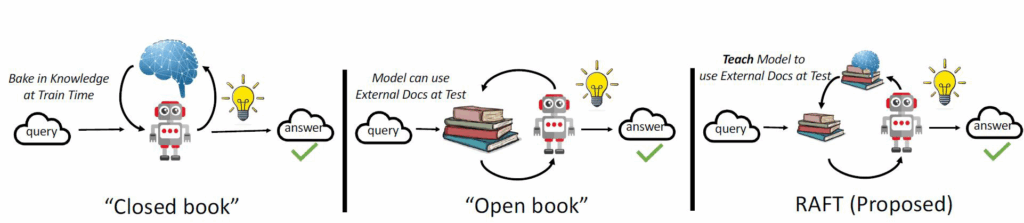
核心思想:如何最好地准备考试?
传统方法的局限性
- 基于微调的方法:通过”学习”来实现”记忆”输入文档或回答练习题而不参考文档
- 基于上下文检索的方法:未能利用固定领域所提供的学习机会,相当于参加开卷考试但没有事先复习
RAFT的创新之处
相比之下,我们的方法RAFT利用了微调与问答对,并在一个模拟的不完美检索环境中参考文档——从而有效地为开卷考试环境做准备。
方法论详解
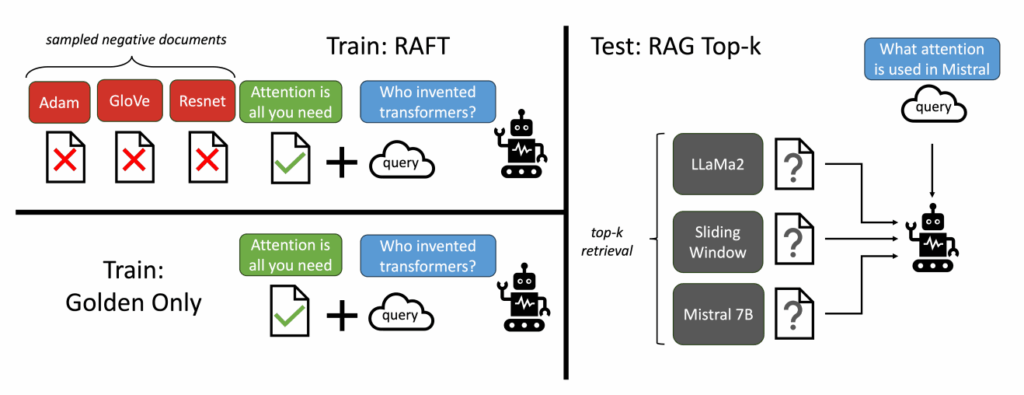
训练策略
让LLMs从一组正面和干扰文档中读取解决方案,这与标准的RAG设置形成对比,因为在标准的RAG设置中,模型是基于检索器输出进行训练的,这包含了记忆和阅读的混合体。
在测试时,所有方法都遵循标准的RAG设置,即提供上下文中排名前k的检索文档。
微调数据集准备样例
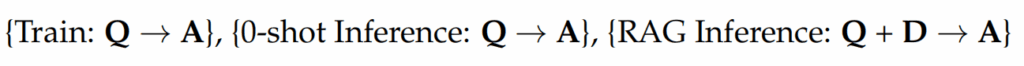
实验结果与性能评估
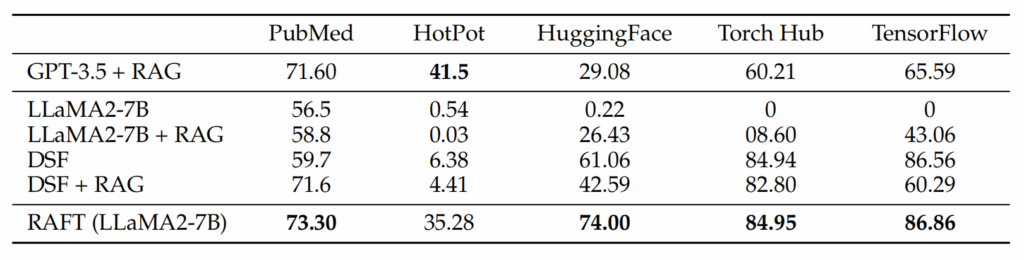
跨领域性能提升
RAFT在所有专业领域的RAG性能上有所提升,涵盖以下多个领域:
- PubMed
- HotPot
- HuggingFace
- Torch Hub
- TensorflowHub
关键发现
- 领域特定微调效果显著:领域特定的微调提高了基础模型的性能
- 持续性优势:RAFT无论是在有RAG的情况下还是没有RAG的情况下,都持续优于现有的领域特定微调方法
- 上下文训练的重要性:这表明了需要在上下文中训练模型的重要性
总结
RAFT方法的核心价值
适应特定领域的挑战:
- 适应特定领域的LLMs对于许多新兴应用至关重要,但如何有效融入信息仍是一个开放问题
技术融合创新:
- RAFT结合了检索增强生成(RAG)和监督微调(SFT),从而提高模型在特定领域内回答问题的能力
抗干扰能力提升:
- 训练模型识别并忽略那些不能帮助回答问题的干扰文档,只关注和引用相关的文档
- 通过在训练中引入干扰文档,提高模型对干扰信息的鲁棒性,使其在测试时能更好地处理检索到的文档
实践资源
训练示例代码:https://github.com/lumpenspace/raft
RAFT方法为RAG系统在特定领域的应用提供了新的优化思路,通过模拟不完美检索环境的训练方式,显著提升了模型在实际应用场景中的表现。